GSoC Week 13 & Week 14 — Making options in git-cat-file honor mailmap!
Well Hello friend 👋🏻
Last week, I got a 2-week extension on my GSoC timeline. Now, I can put that time on completing my git patches and look for bug fixes if any. After a lot of iterations and reviews from my mentors, I submitted my latest patch on git mailing list. Let’s discuss about the implementation!
The Problem
git-cat-file command supports two options called, -s and --batch-check, which return the size of the object that is passed to them. Gitaly uses the following command to get the size of all the objects in a git repo. Even though they can be combined with --use-mailmap option, it doesn’t have any effect on the size they report, as these options don’t report the size the object would have had if the idents were replaced using the mailmap mechanism.
1 | git cat-file --use-mailmap --batch-all-objects --batch-check --buffer --unordered |
Now that Gitaly has the size of the objects, it can read that many bytes when it executes git cat-file --use-mailmap -p <object-sha>.
Now, let’s assume the size for a particular commit object as recorded by Gitaly is 600. But, let’s say that after replacing the idents using mailmap the object size that git cat-file -use-mailmap -p <sha> is 605. In such a scenario, Gitaly will only read 600 bytes instead of 605 bytes. This caused a lot of features to not work after adding --use-mailmap to git cat-file commands in Gitaly.
The best way to solve the problem is by making -s and --batch-check honor the mailmap mechanism when used with --use-mailmap option. That is what I am currently implementing!
Approach to solve the problem
We want -s and --batch-check options to honor mailmap when used with --use-mailmap option. In order to do that, they must read the commit/tag objects. The biggest challenge is to read the commit/tag object without sacrificing performance, as it can be an expensive operation.
Let’s see how git cat-file -s <sha> gets the size of the object. To understand, let’s take a look at the first few lines of a function called do_oid_object_info_extended().
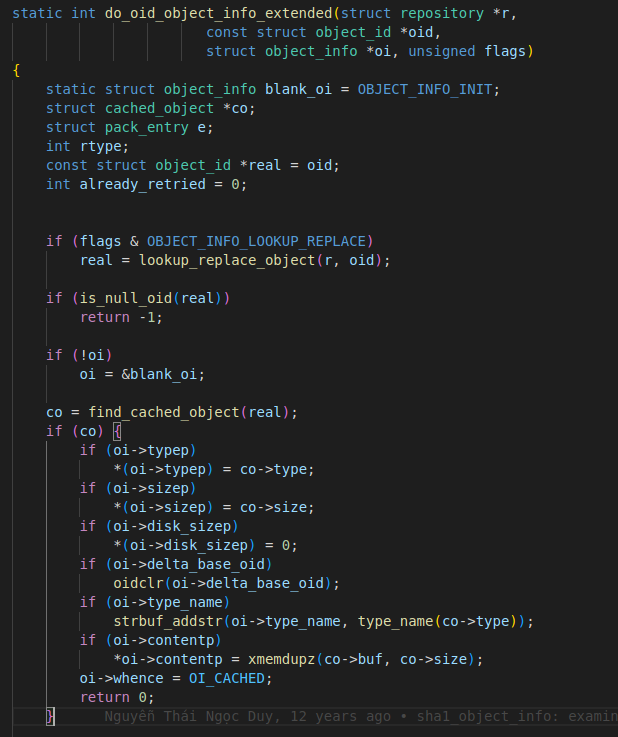
As we can see, there is a call to function find_cached_object(). As the name suggests, it reads the cached git objects. Then, if we found a non-NULL cached object, we initialize various members of object_info structure if they are also not NULL.
The object_info structure looks like the following:
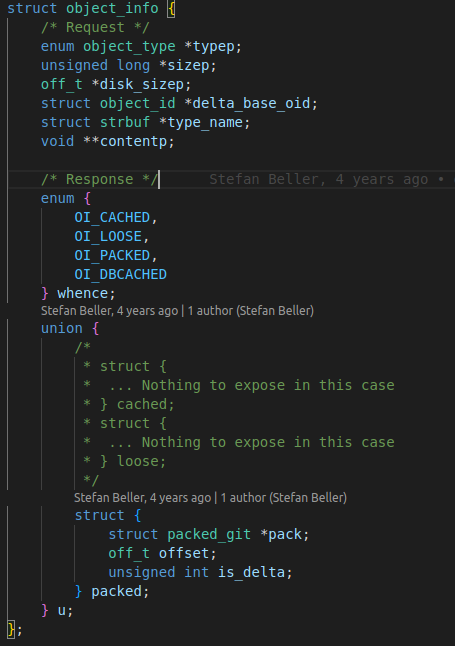
So, the object_info structure has several members like typep, sizep, contentp and some more which are pointers. So, let’s say we want to get the size of an object, we first need to set the sizep field of object_info structure to point to a non-NULL location and then pass it to the do_oid_object_info_extended() function.
That’s pretty much how we get the size of an object when we execute git cat-file -s <sha>. There is just one variance that we don’t directly call do_oid_object_info_extended() function, instead we make a call to oid_object_info_extended() which is nothing but a wrapper for the do_oid_object_info_extended() function. But, I hope I am able to convey the idea here.
Just to make things crystal clear, here is the code which -s option of git-cat-file to get the size:
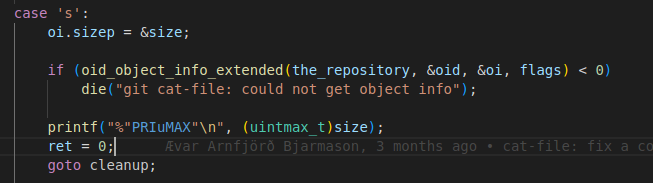
Just, as we discussed, oi is nothing but an instance of the object_info structure. We first made it’s sizep field point to a variable called size and then call oid_object_info_extended() function, which populated the oi.sizep or size variable. And we simply print that to the stdout!
Now, as you might have guessed in order to make it honor the mailmap mechanism, we will have to read the object, for which we will need to read content of the object so that we can replace the idents on it and get the updated size. And to get the contents all we have to do is set the contentp field of object_info struct to point to a char * buffer and then call oid_object_info_extended(). But, just plainly reading the contents for every object can be expensive as tree and blob objects can be considerably larger than the commit /tag objects. So, it would really improve the performance if we could know the type of the object as well. And that is simple as well… I am leaving that for you to guess 😅
Here is how I did it:
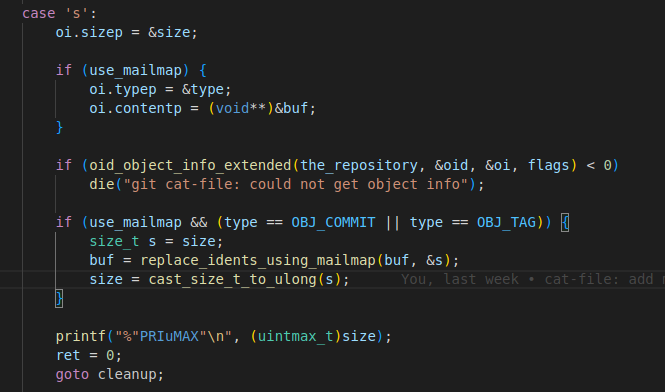
I am setting the reading the type and contents of the object only when -s option is combined with --use-mailmap option. The function replace_idents_using_mailmap() reads the object, replaces idents with their canonical versions and updates the size of the object. That’s how I am enabled -s option to honor mailmap!
I followed a similar approach for --batch-check option as well! Here is the link to my patches in the mailing list: https://lore.kernel.org/git/20220916205946.178925-1-siddharthasthana31@gmail.com/T/#t
I am very grateful for my mentors, Christian and John, for helping me to improve and understand all of these things! I am forever grateful to them!! 🙇
I have submitted my patches to Git’s mailing list as well. I am very happy to have received a very quick review from Junio as well. Thanks a lot, Junio!! 😀
I am currently working on improving the patches based on the reviews and will be sending the v2 very soon!
The road ahead 🛣️
So, my next task will be to:
- Improve my git patches.
- Verify all the features on GitLab work when we enable
--use-mailmapoption forgit-cat-filecommands in Gitaly. I have already tested the contribution graph and some commits. I am working on verifying other features as well!
So yeah, that was the week 13 & week 14. Can’t believe GSoC will be over the next week 😢
Thanks a lot for reading 🙂 Will be back next week with another blog, Peace! ✌🏻